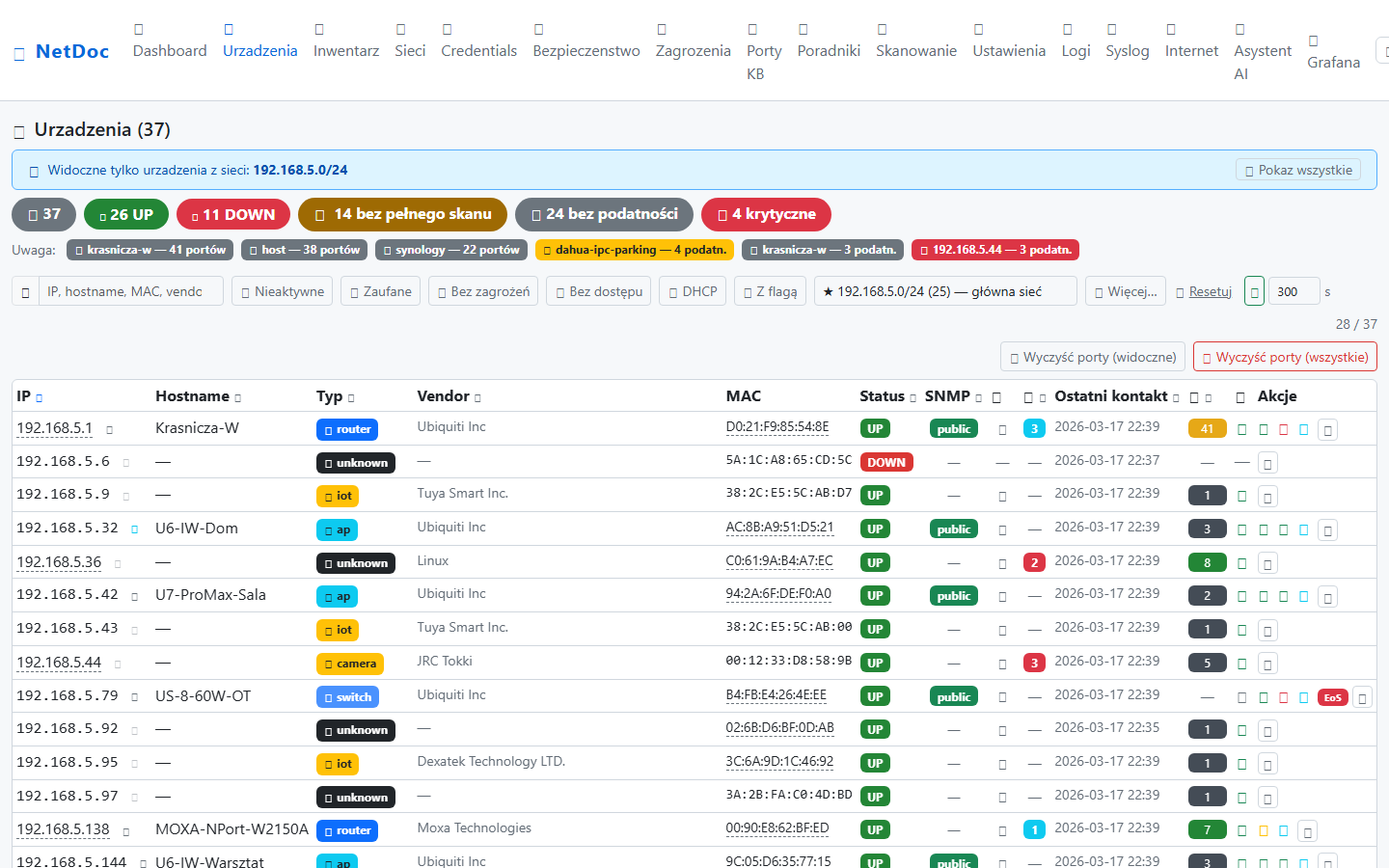
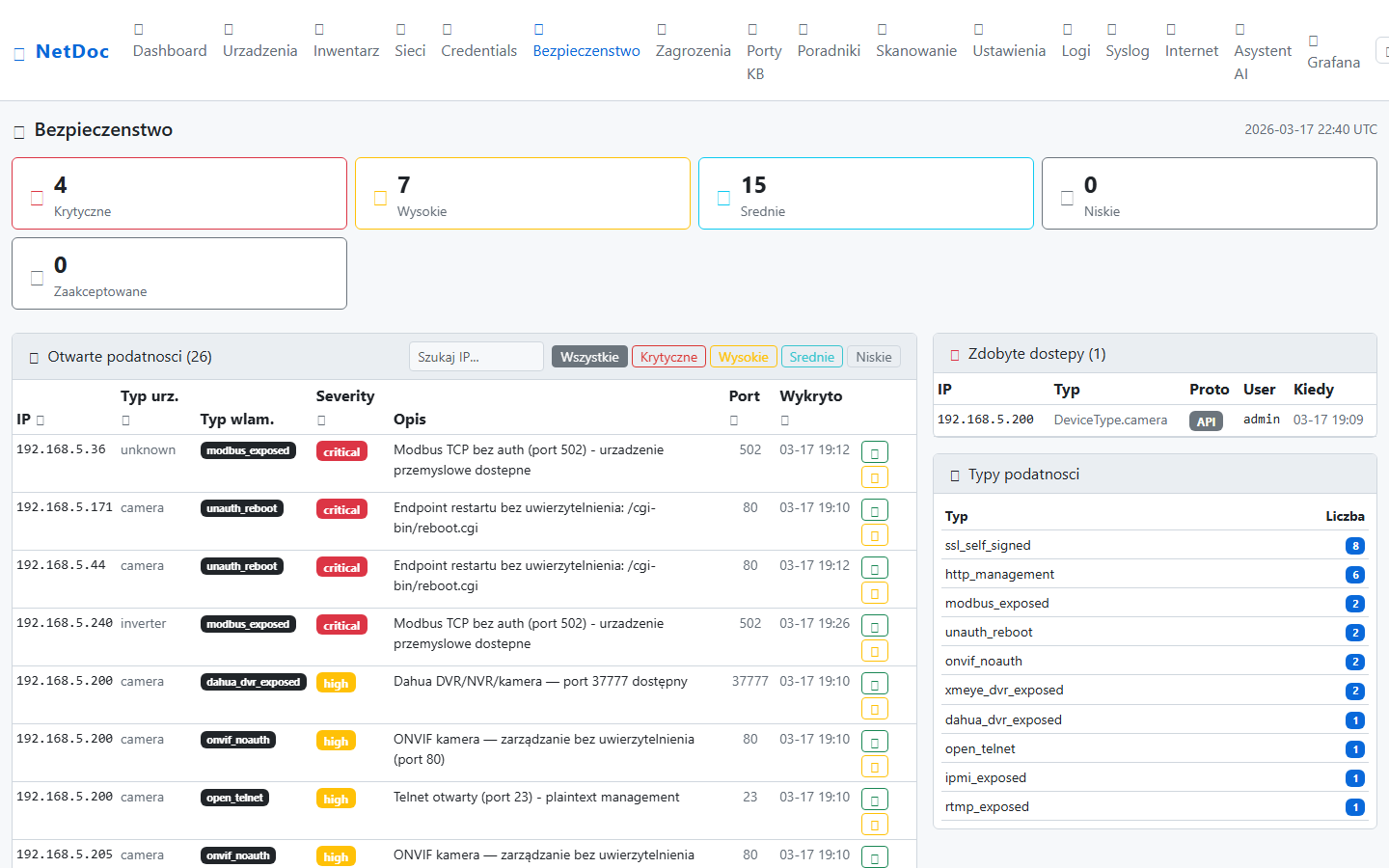
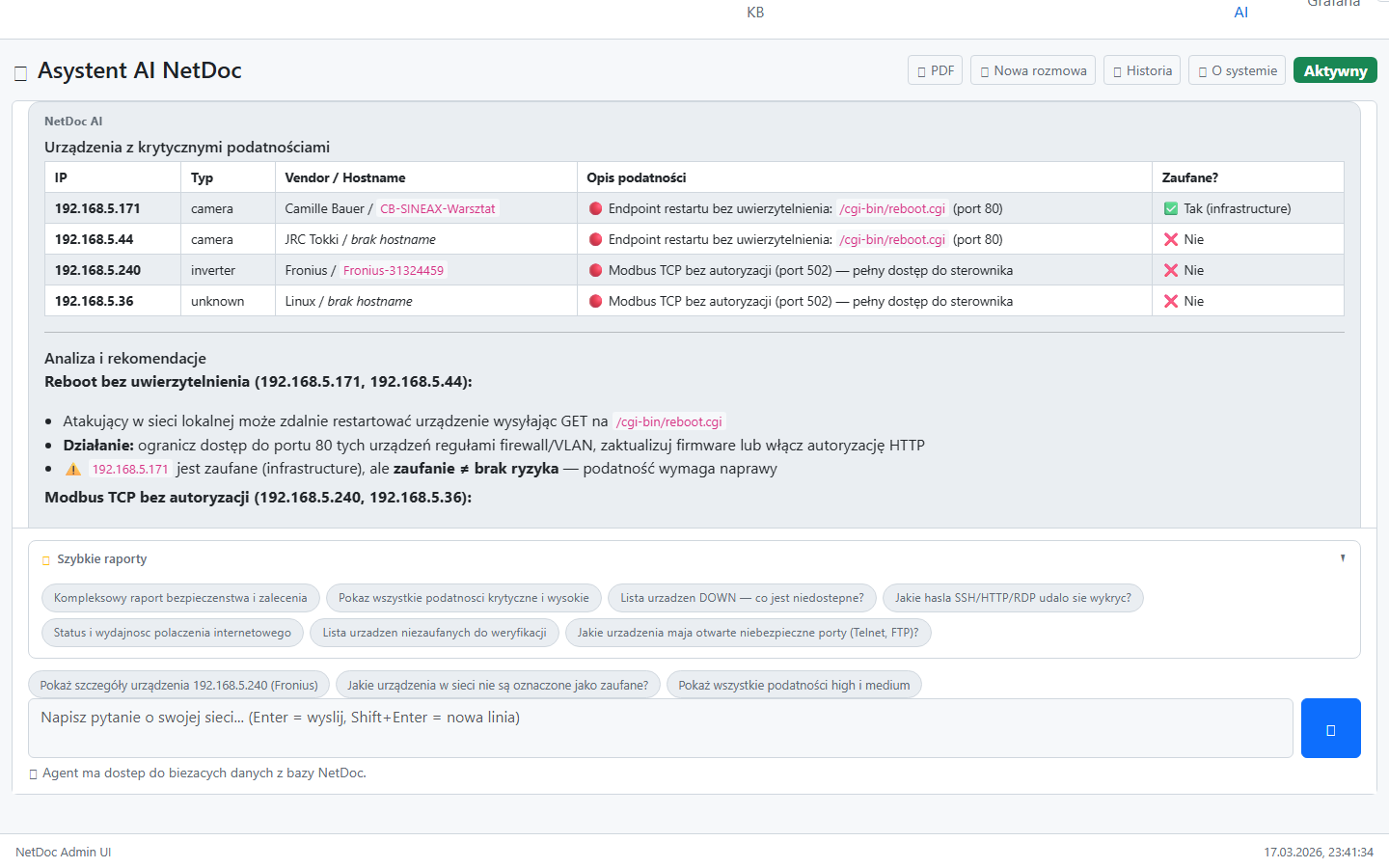
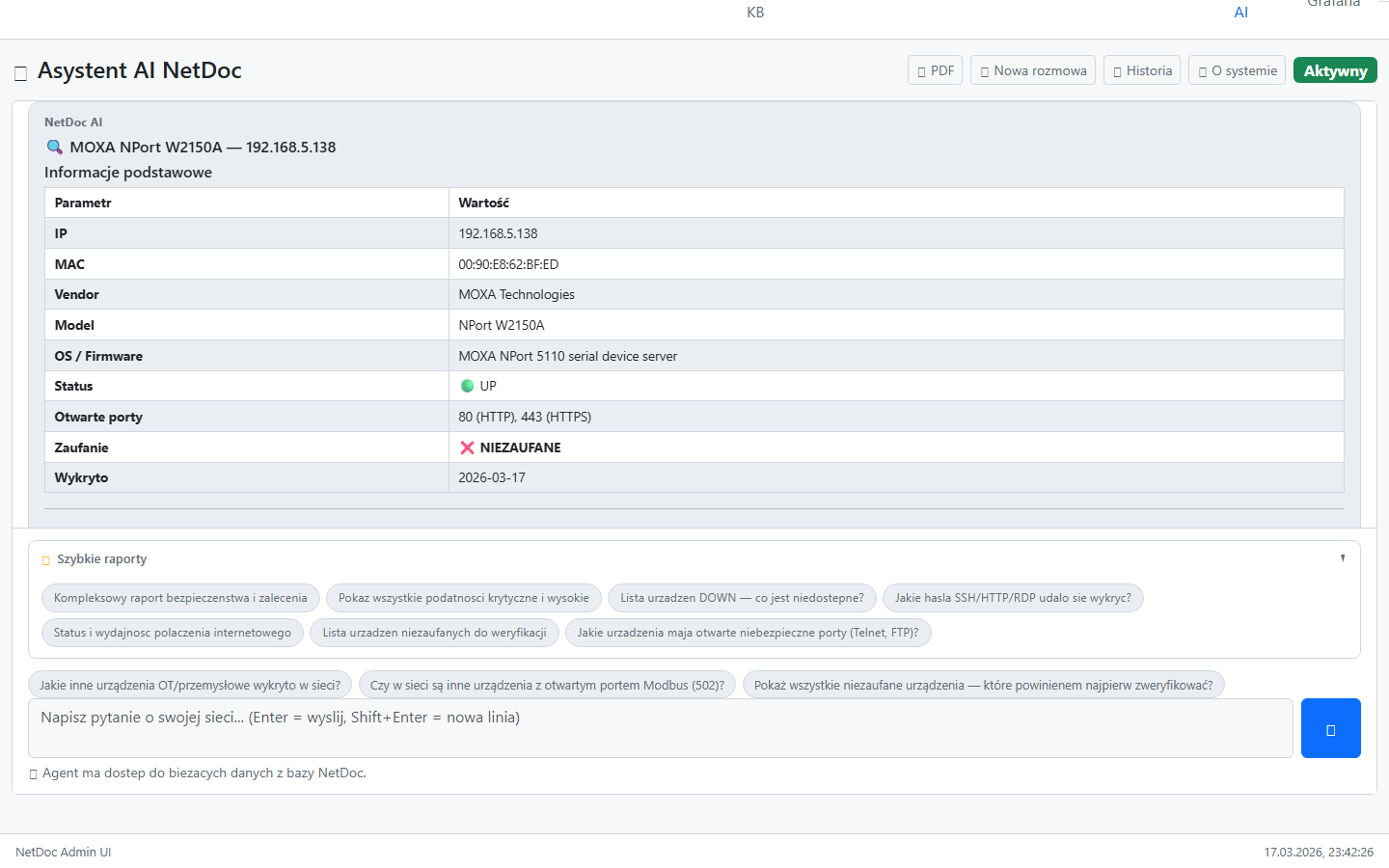
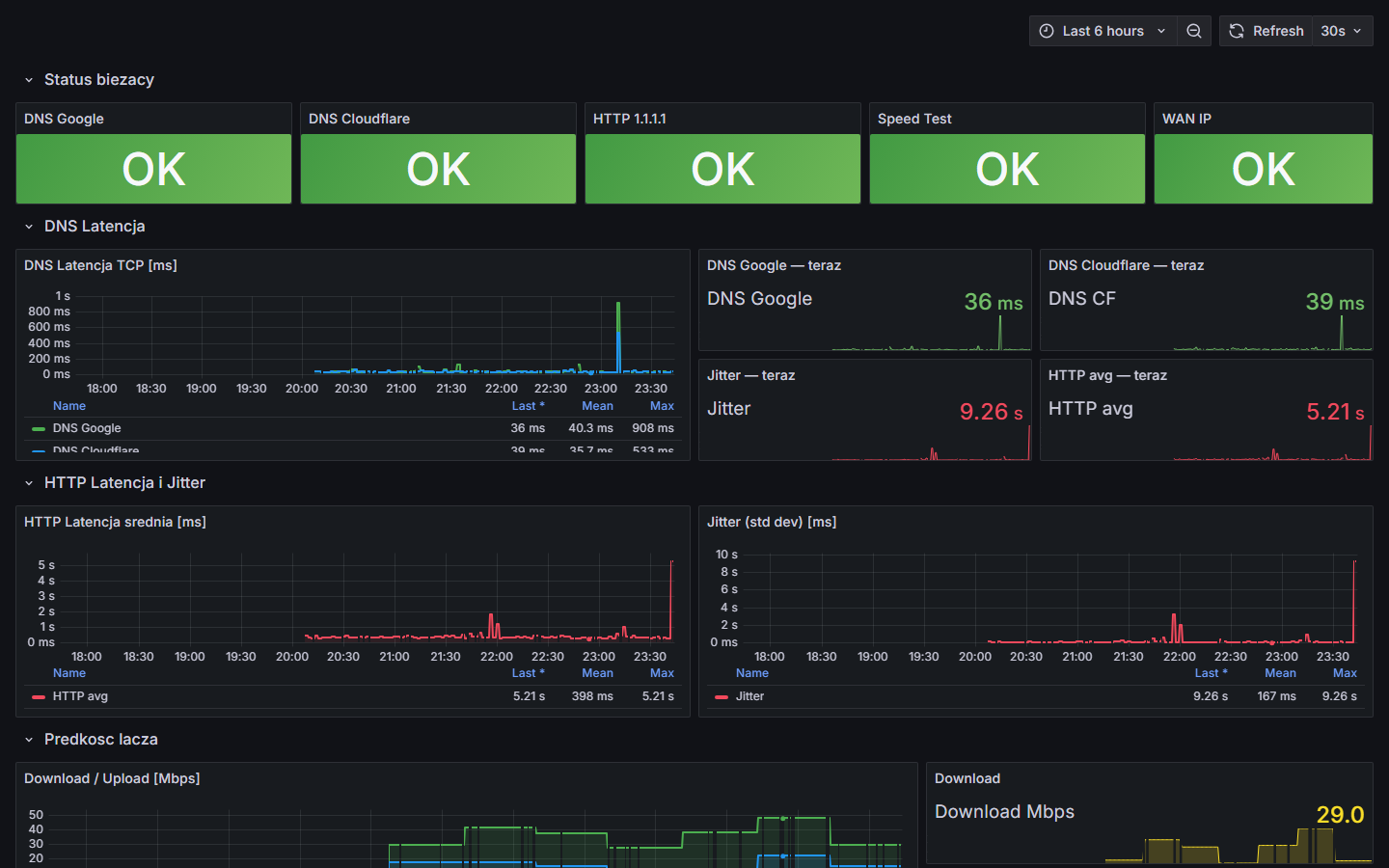
Konkretne scenariusze z życia — jak NetDoc skraca czas diagnozy i zmniejsza koszty.
⚡
Nocne restarty dziesiątek urządzeń — winowajca: aparatura elektryczna
Obiekt biurowy / budynek z monitorowaną infrastrukturą sieciową
Na obiekcie biurowym przez kilka nocy dochodziło do dziwnych incydentów: kamery traciły konfigurację,
switche wymagały ponownego wgrania ustawień, część urządzeń BMS wracała do wartości fabrycznych.
Usterki wyglądały jak losowe — nikt ich nie łączył ze sobą. Każda zgłaszana oddzielnie,
każda leczona objawowo.
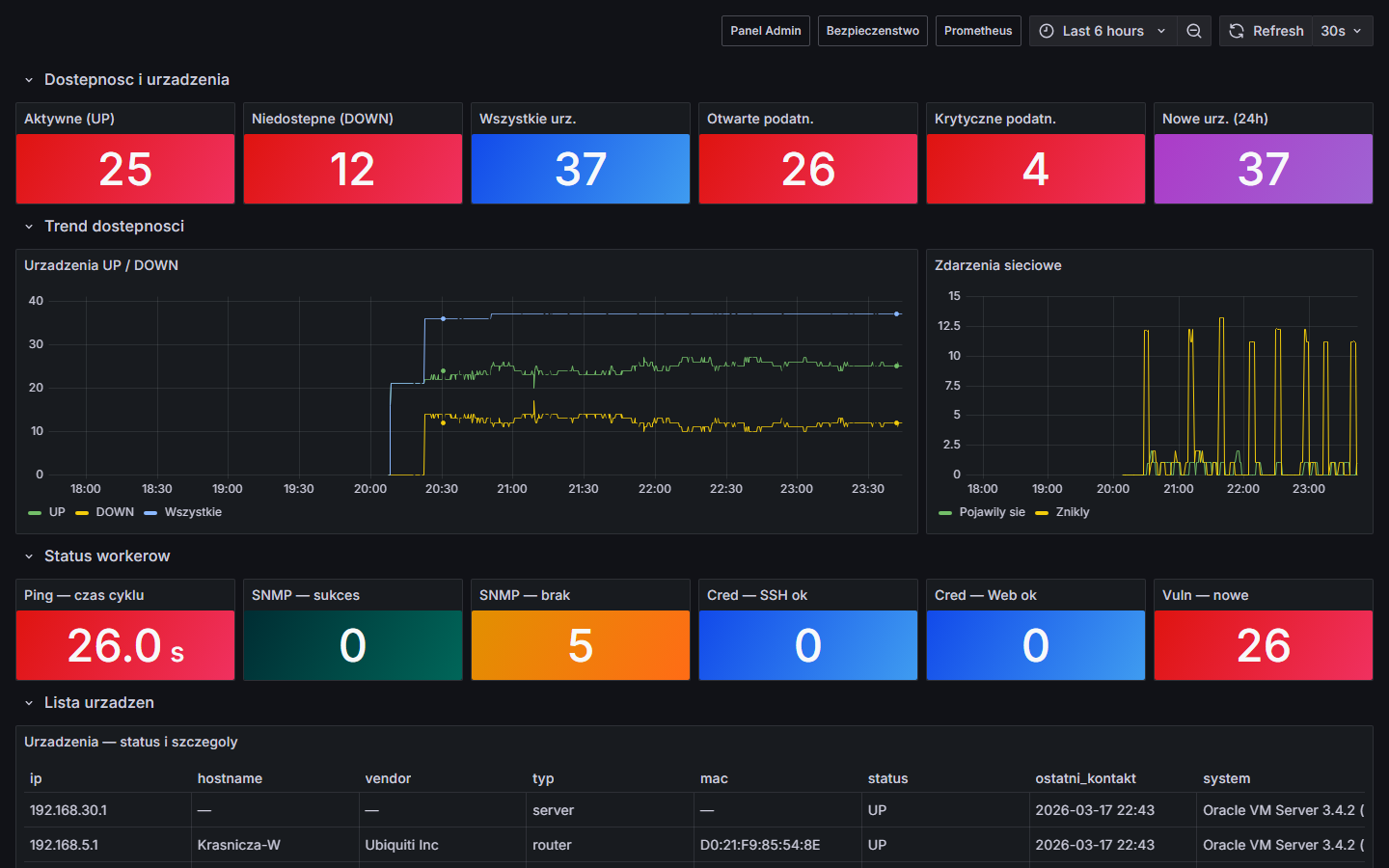
Monitoring pokazał wzorzec który gołym okiem był niewidoczny:
dziesiątki urządzeń znikały z sieci i wracały w tej samej chwili —
o 2:15, 3:42, 4:08 w nocy. Nie jedno urządzenie z błędem, nie awaria switcha — cały segment sieci
gasł i wstawał jednocześnie. To nie był problem IT.
Analiza historii alarmów wskazała na układ przełączania źródeł zasilania,
który w godzinach nocnych (mniejsze obciążenie budynku) generował serie krótkich zaników.
Finalnie wymiana uszkodzonej aparatury elektrycznej zakończyła tygodnie "tajemniczych awarii".
Jak wyglądały alarmy w monitoringu
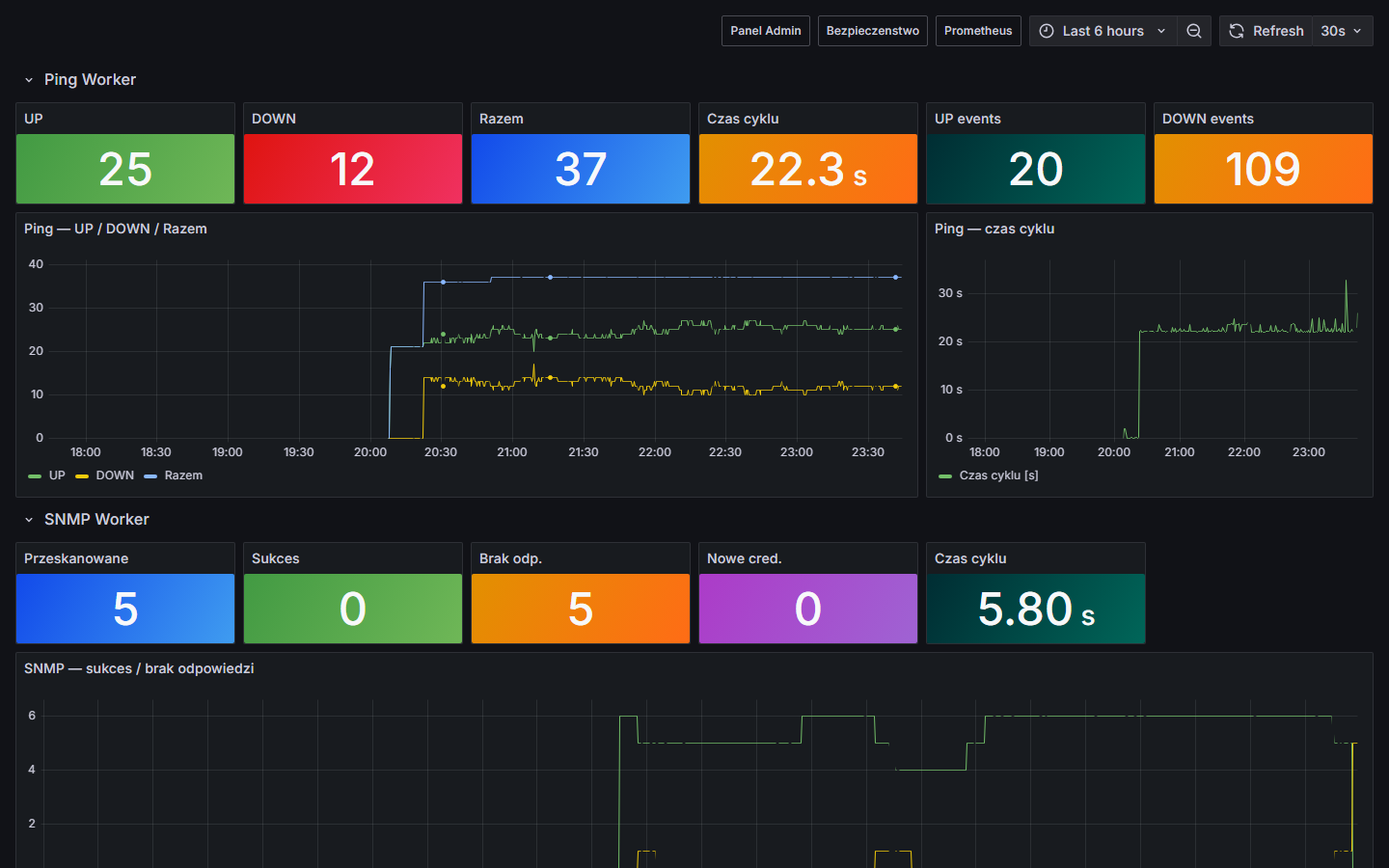
02:15
↓ DOWN
31 urządzeń jednocześnie (kamery, switche, sterowniki BMS)
02:15
↑ UP
31 urządzeń — powrót po ~8 sekundach
03:42
↓ DOWN
29 urządzeń jednocześnie
04:08
↓ DOWN
34 urządzenia jednocześnie
❌ Bez monitoringu
Każda usterka leczona osobno — reset urządzenia, wgranie konfiguracji, wizyta serwisu. Tygodnie objawowego leczenia skutków bez znalezienia przyczyny. Koszty serwisowe rosną, problem wraca.
✓ Z monitoringiem
Historia alarmów pokazuje wzorzec: dziesiątki urządzeń w tym samym segmencie, w tych samych godzinach. Diagnoza wskazuje zasilanie — nie IT. Elektryk zamiast kolejnego resetu urządzeń.
💡 Kluczowa zasada:
monitoring IT nie musi "widzieć" usterki elektrycznej bezpośrednio.
Wystarczy że rejestruje korelację zdarzeń —
wiele urządzeń w tym samym czasie, regularny wzorzec nocny, brak indywidualnej przyczyny technicznej.
To punkt zaczepienia, który kieruje diagnozę we właściwą stronę i oszczędza tygodnie szukania w złym miejscu.
⏱ Tygodnie objawowego leczenia → jedna rozmowa z elektrykiem.
🔓
Przejęcie sieci przez jedno domyślne hasło
Firma produkcyjna / biuro / dowolna sieć z niezmienionym hasłem fabrycznym
Switch zarządzalny z domyślnym hasłem admin/admin lub router z cisco/cisco
to nie tylko „słabe zabezpieczenie" — to pełna kontrola nad siecią.
Osoba z dostępem do przełącznika może: włączyć port mirroring i podsłuchiwać cały ruch w sieci,
zmienić tablice routingu i przekierować ruch przez własną maszynę, wyłączyć porty kluczowych
urządzeń, otworzyć backdoor VPN lub po prostu wyeksportować konfigurację z hasłami innych urządzeń.
W realnych przypadkach do naruszenia bezpieczeństwa wystarczył dostęp do jednego urządzenia
z domyślnym hasłem — pracownik, podwykonawca z dostępem do sieci WiFi, a nawet fizyczny dostęp do gniazda sieciowego.
Kamery z admin/admin to nie tylko podgląd obrazu — często mają dostęp do dalszej części sieci i serwują jako punkt wejścia.
Typowy łańcuch eskalacji
1 urządzenie z domyślnym hasłem
→
dostęp do konfiguracji sieci
→
podsłuch / przekierowanie ruchu
→
hasła innych systemów
→
pełne przejęcie infrastruktury
❌ Bez NetDoc
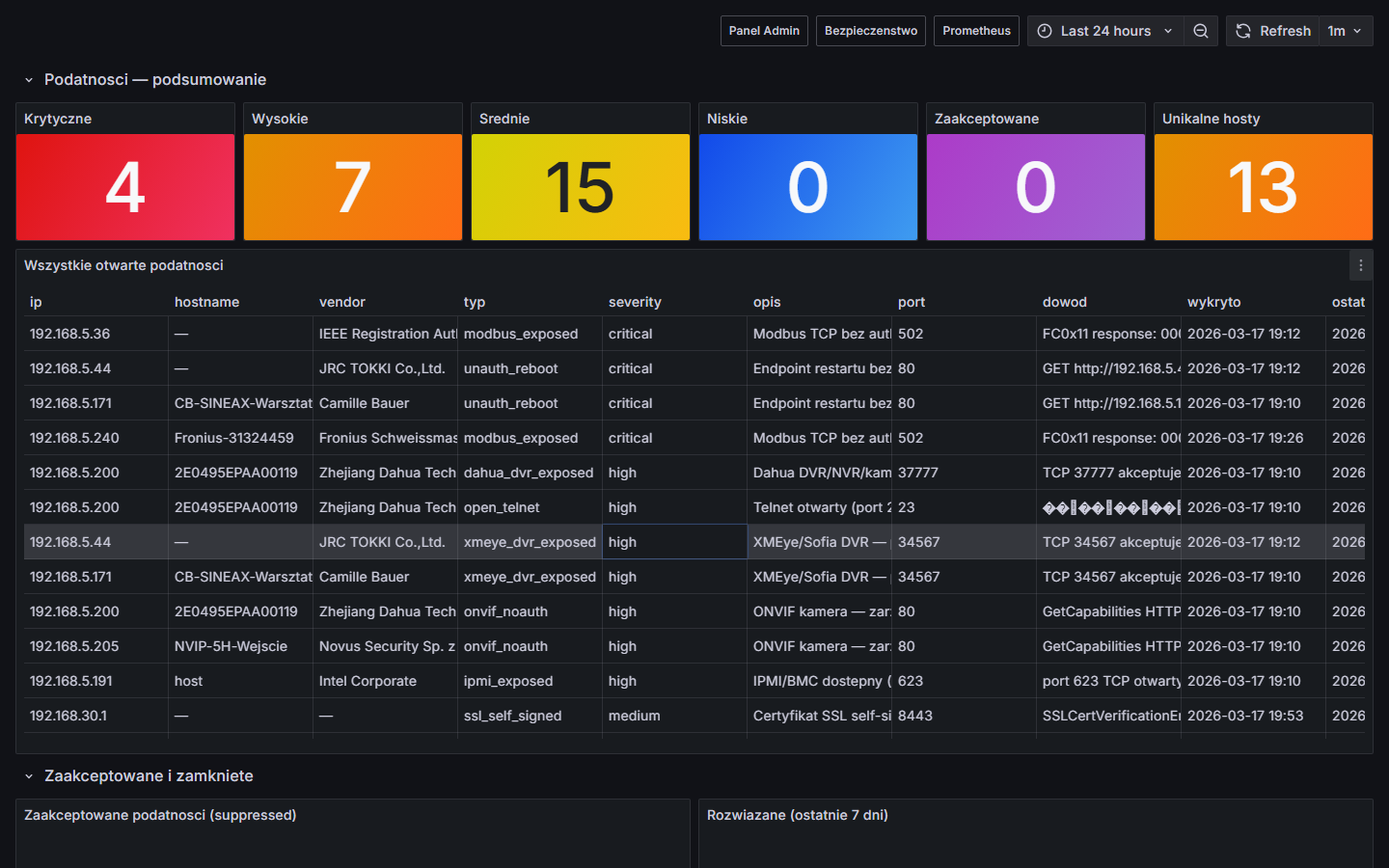
Nie wiesz że urządzenie ma domyślne hasło. Nikt tego nie sprawdzał. Problem zostaje odkryty dopiero po incydencie — albo wcale.
✓ Z NetDoc
Automatyczne testy 170+ par fabrycznych przy każdym cyklu skanowania. Przy odkryciu: alert z dokładnym IP, protokołem i parą login/hasło. Możesz zareagować zanim pojawi się problem.
🔑 Domyślne hasła to #1 wektor wejścia w audytach sieci SMB i przemysłowych.
📡
Tajemnicze awarie sieci — winowajca: obcy serwer DHCP
Biuro / sieć z urządzeniami DHCP / każda sieć z nieznanym sprzętem
Pracownik podłącza do sieci firmowej własny router WiFi (np. TP-Link w trybie routera, nie AP)
— albo technik chwilowo zostawia urządzenie testowe z aktywnym DHCP. Router zaczyna
rozgłaszać własne oferty DHCP w całej sieci LAN.
Część urządzeń odbiera ofertę od obcego serwera i dostaje adresację z zupełnie innego zakresu
— np. 192.168.0.x zamiast firmowego 10.1.0.x.
Komputery tracą połączenie z serwerami plików, drukarkami, systemem ERP.
Inne urządzenia — szczególnie IoT i kamery — nie mogą się dogadać z nową podsiecią
i praktycznie wypadają z sieci.
Diagnoza bez narzędzi zajmuje długo — problem jest niewidoczny, losowy i wygląda jak
„coś się samo zepsuło". Sprawdzasz kable, restartujesz switche, dzwonisz do dostawcy internetu.
❌ Bez NetDoc
Nie wiesz że w sieci jest drugi serwer DHCP. Logujesz się na każdy komputer, porównujesz adresy IP ręcznie, szukasz igły w stogu. Diagnoza: kilka godzin, najczęściej sprowadza się do restart-u routera głównego.
✓ Z NetDoc
NetDoc widzi: nagłe pojawienie się nowej podsieci (192.168.0.x) — ostrzeżenie o nieznanej adresacji w sieci. W logu: nowy host z adresem MAC — identyfikujesz rogue router w ciągu minut po MAC OUI (np. TP-Link Technologies).
💡 Jak NetDoc pomaga w tym scenariuszu:
wykrycie nowej nieznanej podsieci z alertem w logach,
OUI lookup po MAC adresie wskazuje producenta i typ podejrzanego urządzenia,
historia skanów pokazuje dokładnie kiedy nieznany host pojawił się w sieci —
co pozwala powiązać incydent z konkretną osobą lub zdarzeniem.
📡 Rogue DHCP to jeden z częstszych problemów w sieciach biurowych bez segmentacji.
🧹
Sobotnie sprzątanie wyłączyło całe biuro — technik zdążył przed poniedziałkiem
Biuro z serwerownią / firma bez całodobowego dyżuru IT
Sobotni poranek. Ekipa sprzątająca podłącza odkurzacz do gniazdka w korytarzu przy serwerowni.
Przeciążenie wyrzuca różnicówkę — i cała szafa: serwer, router, switch, NAS, wyłącza się.
Biuro martwe. Nikt nie wie. Sprzątaczki kończą pracę i wychodzą.
Bez monitoringu ten scenariusz kończy się w poniedziałek rano: 8:00, pracownicy przychodzą,
nic nie działa — serwer plików, poczta, ERP, VPN. Panika, telefony do IT,
technik jedzie w trybie awaryjnym. Przestój całego biura od rana.
Z monitoringiem alert przychodzi w sobotę o 9:23 — jest jeszcze cały weekend na spokojną reakcję.
Jak wyglądała oś czasu
Sob. 09:23
↓ DOWN
serwer, router, switch, NAS — wszystko jednocześnie
Sob. 09:23
🔔 ALERT
Telegram: "4 hosty niedostępne — prawdopodobna awaria zasilania"
Sob. 11:45
✓ FIX
technik na miejscu, różnicówka przywrócona, systemy wstają
Pon. 08:00
✓ OK
pracownicy przychodzą — wszystko działa, nikt nic nie wie
❌ Bez monitoringu
Problem wykryty w poniedziałek rano przez pracowników. Przestój całego biura od otwarcia. Technik jedzie w trybie awaryjnym. Wznowienie pracy po kilku godzinach — straty wizerunkowe i finansowe.
✓ Z monitoringiem
Alert w ciągu sekund od zdarzenia. Technik reaguje w weekend, spokojnie przywraca zasilanie. Poniedziałkowy poranek przebiega normalnie. Zero przestoju, zero nerwów w biurze.
💡 Kluczowa wartość:
monitoring nie zapobiegł awarii zasilania — tego nie zrobi żadne oprogramowanie.
Ale skrócił czas od zdarzenia do reakcji z ~47 godzin do ~2 godzin.
Różnica między "nikt nie wiedział przez weekend" a "technik zdążył przed poniedziałkiem"
to dokładnie tyle, ile wart jest alert w odpowiednim momencie.
⏱ 47 godzin nieświadomości → 2 godziny do naprawy.
🌐
Awaria między operatorami — Helpdesk uprzedzony, klienci poinformowani, zanim zadzwonili
Operator / dostawca usług / datacenter obsługujący wielu klientów
Problem między operatorami internetowymi — routing BGP, awaria peering, awaria łącza tranzytowego.
Niezależnie od przyczyny efekt jest ten sam: kilkanaście minut przerwy, podczas których
~300 firm traci dostęp do usługi.
Serwery działają, datacenter działa, wina leży poza infrastrukturą operatora — ale klienci tego nie wiedzą.
Widzą tylko: "nie działa".
Bez monitoringu przez pierwsze kilkanaście minut nikt po stronie operatora nic nie wie.
Klienci dzwonią jeden po drugim. Helpdesk jest zaskoczony, nie ma informacji, nie może potwierdzić ani zaprzeczyć.
Frustracja rośnie. Pierwsze "dlaczego was nie stać na porządne łącze" pojawia się po 3 minutach.
Z monitoringiem cały łańcuch komunikacji uruchamia się automatycznie
— zanim którykolwiek klient zdąży podnieść słuchawkę.
Automatyczny łańcuch reakcji — pierwsze 3 minuty
T+0s
↓ DOWN
monitoring wykrywa utratę connectivity — 300 endpointów niedostępnych
T+15s
🔔 ALERT
Helpdesk otrzymuje: "awaria łącza, ~300 klientów odciętych, przyczyna zewnętrzna"
T+30s
📋 PAGE
status page aktualizuje się automatycznie: "Prowadzimy prace — śledzimy incydent"
T+45s
📢 POST
social media: "Jesteśmy świadomi problemu, pracujemy nad rozwiązaniem"
T+3min
📞 ——
pierwsze telefony od klientów — Helpdesk już wie, status page już aktywny
T+17min
✓ UP
routing przywrócony przez operatora upstream — status page: "Rozwiązano"
❌ Bez monitoringu
Helpdesk zasypany telefonami z których nic nie wynika. Inżynierowie diagnozują w pośpiechu. Klienci słyszą "sprawdzamy" przez 20 minut. Wrażenie chaosu — nawet jeśli awaria trwała chwilę. Pierwsze negatywne opinie w mediach społecznościowych.
✓ Z monitoringiem
Helpdesk odbiera telefony z gotową odpowiedzią. Klienci którzy zobaczyli status page — nie dzwonią w ogóle. Inżynierowie dostają alert z kontekstem, nie z paniki. Awaria 17 minut — komunikacja profesjonalna od pierwszej sekundy.
💡 Kluczowa zasada:
klientów nie irytuje awaria — irytuje brak informacji o awarii.
Monitoring zintegrowany z komunikacją (status page, social media, Helpdesk)
zmienia reakcję z "co się dzieje, dlaczego nikt nic nie wie"
na "widzę że wiedzą i pracują nad tym".
To różnica między utratą zaufania a budowaniem go w trudnym momencie.
🌐 Awaria 17 minut — komunikacja profesjonalna od pierwszej sekundy.
🌡️
Klimatyzacja w serwerowni przestała działać — alert zanim sprzęt się uszkodził
Serwerownia / szafa rack / każde pomieszczenie z czułym sprzętem
Latem, w piątek po południu, w serwerowni uszkodził się agregat klimatyzacyjny.
Temperatura w pomieszczeniu zaczęła rosnąć. Serwery, switche i zasilacze UPS
pracują dalej — nie sygnalizują żadnego problemu w sieci.
Nikt nic nie wie. Budynek pustoszeje na weekend.
Bez monitoringu temperatury scenariusz jest przewidywalny:
w sobotę rano temperatura przekracza próg bezpiecznej pracy,
procesory zaczynają throttling, dyski zwalniają, serwery wyłączają się awaryjnie
lub — co gorsza — pracują w przeciążeniu termicznym aż do uszkodzenia.
Wymiana spalonego sprzętu to tysiące złotych i dni przestoju.
Z czujnikiem temperatury i monitoringiem alert wychodzi już przy pierwszym wzroście —
wskazane osoby reagują zanim temperatura osiągnie poziom krytyczny.
Jak wygląda eskalacja alertów temperaturowych
15:40
⚠ WARN
temperatura serwerowni: 28°C (próg ostrzegawczy) — SMS + Telegram do administratora
16:05
🔴 CRIT
temperatura: 34°C (próg krytyczny) — alert e-mail + SMS do managera i serwisu AC
16:05
📈 TREND
wykres: +6°C w 25 minutach — prognoza przekroczenia 40°C za ~35 minut
16:30
✓ ACT
technik na miejscu — klimatyzacja przywrócona awaryjnie, temperatura spada
Weekend
✓ OK
serwery pracują normalnie — sprzęt bez uszkodzeń
❌ Bez monitoringu temperatury
Nikt nie wie. Temperatura rośnie przez cały weekend. W poniedziałek serwery nie odpowiadają lub są uszkodzone. Wymiana sprzętu, odtwarzanie danych z backupu, kilka dni przestoju firmy.
✓ Z monitoringiem temperatury
Alert przy pierwszym wzroście temperatury. Eskalacja do kolejnych osób jeśli nikt nie reaguje. Technik interweniuje w ciągu godziny. Sprzęt bez uszkodzeń, firma nie wie że cokolwiek się stało.
💡 Koszt czujnika temperatury vs koszt przegrzania:
czujnik środowiskowy z integracją monitoringu to wydatek rzędu kilkuset złotych.
Wymiana uszkodzonych termicznie serwerów, dysków i przełączników —
to dziesiątki tysięcy złotych i kilka dni przestoju.
Monitoring nie naprawia klimatyzacji — ale daje czas żeby to zrobić zanim będzie za późno.
🌡️ Kilkaset złotych na czujnik — vs dziesiątki tysięcy na wymianę sprzętu.
📡
Brak zasilania na nadajniku — klienci poinformowani zanim zaczęli dzwonić
Operator internetu radiowego / WISP / dostawca usług do wielu lokalizacji
Operator internetu radiowego obsługuje kilkadziesiąt lokalizacji — maszty, nadajniki na dachach,
szafy teletechniczne. W jednej z lokalizacji monitoring traci kontakt z całym sprzętem naraz:
routerem, switchem, access pointami. Wszystko jednocześnie — klasyczny objaw braku zasilania.
Kilkudziesięciu abonentów w promieniu nadajnika właśnie straciło internet.
Bez automatyzacji scenariusz jest zawsze taki sam: klienci próbują połączenia, nie ma internetu,
dzwonią do BOK jeden po drugim. Konsultant nie wie co się stało, odsyła do technika,
technik jedzie bez kontekstu. Przez pierwsze 30 minut firma wygląda jak ktoś
kto sam nie wie co się dzieje we własnej sieci.
Z monitoringiem i automatyczną notyfikacją — zanim którykolwiek klient zdąży wybrać numer,
ma już e-mail z informacją że operator wie o problemie i technicy są w drodze.
Automatyczny e-mail do klientów — wysyłany w ciągu 60 sekund od wykrycia
Temat: Informacja o przerwie w usłudze — lokalizacja Kowalew
Szanowni Państwo,
nasz system monitoringu wykrył brak kontaktu ze sprzętem sieciowym obsługującym Państwa lokalizację.
Prawdopodobną przyczyną jest brak zasilania na obiekcie.
Technicy zostali już powiadomieni i udają się na miejsce w celu sprawdzenia i przywrócenia usługi.
Będziemy informować o postępach. Przepraszamy za utrudnienia.
— wysłano automatycznie przez system monitoringu | godz. 14:07
Oś czasu
14:06
↓ DOWN
monitoring: brak kontaktu z 4 urządzeniami w lokalizacji — prawdopodobne zasilanie
14:07
📧 MAIL
automatyczny e-mail do 47 abonentów w zasięgu nadajnika
14:07
🔔 SMS
alert do technika dyżurnego z lokalizacją i listą urządzeń bez kontaktu
14:15
📞 ——
pierwsze telefony od klientów — BOK: "tak, wiemy, technicy w drodze"
15:40
✓ UP
zasilanie przywrócone — monitoring potwierdza powrót urządzeń
15:41
📧 INFO
automatyczny e-mail do klientów: "usługa przywrócona, dziękujemy za cierpliwość"
❌ Bez monitoringu i automatyzacji
Klienci odkrywają awarię sami. BOK zasypany telefonami od osób które nie wiedzą dlaczego nie ma internetu. Konsultant nie ma informacji. Wrażenie chaosu i braku kontroli nad własną siecią. Opinie w stylu "nie wiedzą co się u nich dzieje".
✓ Z monitoringiem i automatyzacją
Klienci dostają e-mail zanim odkryją awarię. BOK odbiera telefony z gotową odpowiedzią. Technik jedzie ze znajomością sytuacji. Awaria ta sama — odbiór klientów zupełnie inny.
💡 Wizerunek buduje się w trudnych momentach:
każdy operator ma awarie. Różnica między tym który traci klientów a tym który buduje lojalność
leży w jednym: czy klient dowiaduje się od Ciebie czy od swojego braku internetu.
Automatyczna notyfikacja przy awarii kosztuje zero — a zmienia całkowicie postrzeganie firmy.
📡 Klient dowiaduje się od Ciebie — nie od braku internetu.